
Taking baby-developer steps
22.05.03.push_swap - 정렬 알고리즘 최적화-3 본문
현재 300개 이상의 Input에서 명령어 사용 수가 5500을 넘고, 500개 이하의 정렬에서 5500개 이하의 명령어를 사용해 stack을 정렬하는것이 목표이므로, 먼저 500개의 input을 넣고 sort_big() 함수의 단계별로 사용되는 명령어의 수를 출력해봤다.

생각보다 두개가 섞여있는 구간에서 한 구간을 빼내고, 이 구간을 a스택에서 정렬하는 부분에서 명령어 소요가 많았다.
단계별로 제일 명령어가 적었던 구간은, a_stack에 ㅁ구간을 빼놓은 다음에 그곳에서 정렬하는 부분이이었다.
내 알고리즘은 특성상 명령어를 합칠 수 있는 구간이 발생하지 않기 때문에, 명령어를 합치는 과정을 통해 최적화를 하는 효과는 기대할 수가 없다.
먼저, 현재 내 push_swap 프로그램에서는 이미 정렬된 input에 대해 아무 출력도 하지 않는 처리가 되어있지 않았으므로, check_sorted 함수를 만들어, 이미 정렬되어 있는 input에 대해서는 종료 처리를 했다.

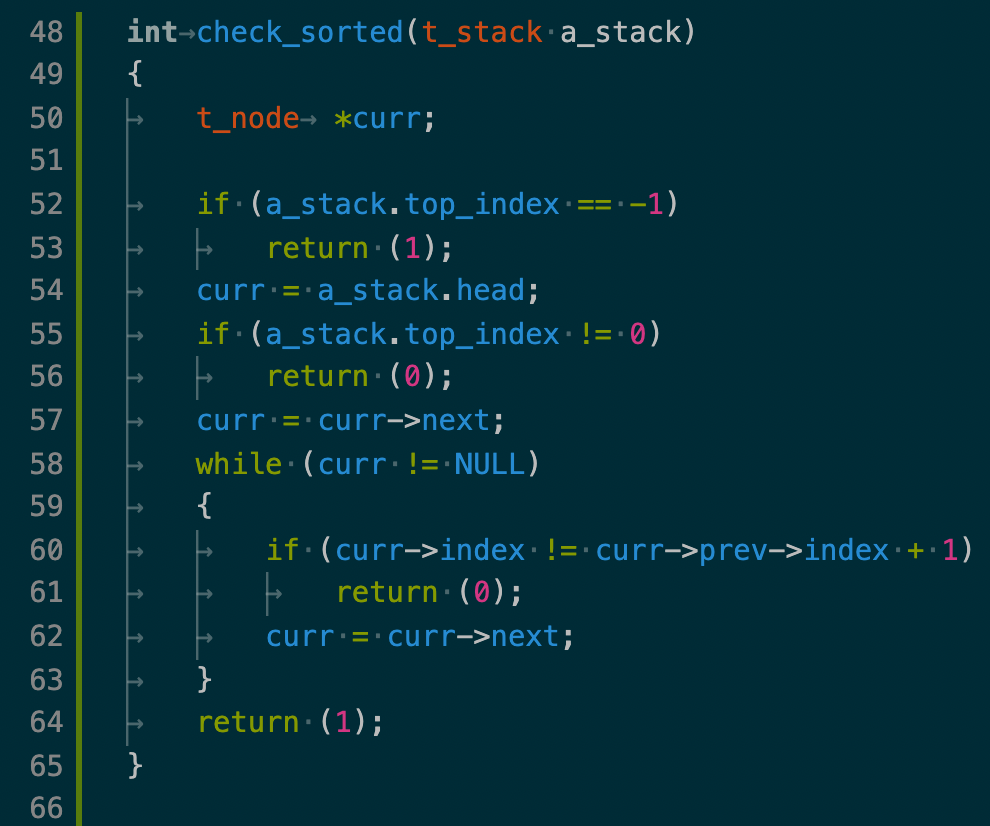

이 종료 처리와 관련해서, exit 함수 내에서 할당되어있는 메모리까지 모두 정리해서 종료 시켜 준다고 알고 있기 때문에 따로 할당되어있는 메모리 들을 할당 해제하지 않으려고 하는데 이에 대해서 평가자와 의견이 맞지 않을 수도 있다고 판단해서, 일단은 주석으로 해당부분을 메모해두고, 후에 최적화를 마친 후 평가를 준비하면서 exit 함수에 대해서도 좀 알아보고 leaks 확인 등을 통해 관련 내용을 보충해 보고 판단할 생각이다.
현재 300개 이상, 500개 이하의 Input에서 과제에서 요구하는 최소값을 충족하지 못하므로, 300개~500개의 구간에서 각 청크(ㄱ,ㄴ,ㄷ,ㄹ,ㅁ)를 260개 이하의 인풋이 들어올때의 정렬방법을 써서 각 청크를 다시 5개의 구간으로 나눠 a_stack에서 정렬해 보려고 한다.
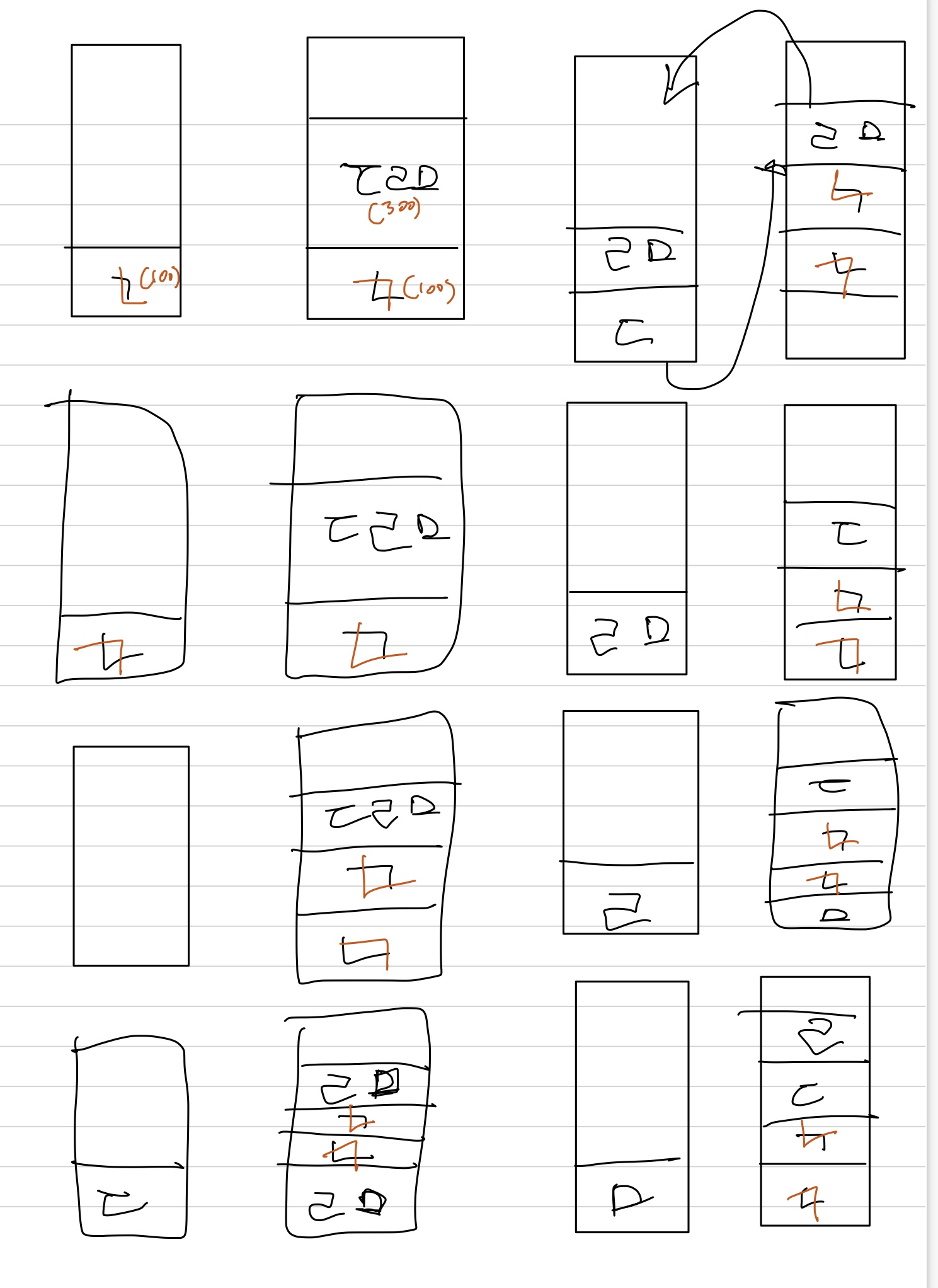
위에서 두개가 섞인 구간 + a_stack에 다른 구간의 값이 있을 때가 특히 명령어의 낭비가 심했던거 같아서, 위와 같이 각 구간이 비어있는 a_stack에서 단독 정렬 될 수 있게 해보려고 한다.
'Logs > 학습 log' 카테고리의 다른 글
| 22.05.05.push_swap - 정렬 알고리즘 최적화-5 (0) | 2022.05.05 |
|---|---|
| 22.05.04.push_swap - 정렬 알고리즘 최적화-4 (0) | 2022.05.04 |
| 22.04.30. push_swap - 정렬 알고리즘 최적화-2 (0) | 2022.04.30 |
| 22.04.29. push_swap - 정렬 알고리즘 최적화-1 (0) | 2022.04.29 |
| 22.04.28. push_swap - 정렬 알고리즘 최적화 (0) | 2022.04.28 |



